
Turning data into decisions: How AI is evolving analytics
Imagine a teammate who’s always available, quick to respond, and unusually good at explaining complex systems in simple terms. One that understands your operational data, can investigate production issues, answer business questions, and help teams navigate millions of events flowing through your systems every day.
That’s LakeBot.
During our monthly team hackathon in November 2025, we set out to connect an LLM agent to our data lake. The goal was to see whether such an agent could help us spend less time on ad-hoc analysis and more time building tools and infrastructure. What started as an experiment quickly evolved into a tool that now helps teams across the company work more efficiently and make better data-driven decisions.
Scaling data with the business
Our organization, Npay, part of Nexi Digital Finland, was formed when Nexi acquired several companies, including the Finnish paytech startup Poplapay.
At Poplapay, data and analytics for development and technical support were built around an OpenSearch and Kibana setup. It worked well for a time, but as the organization grew into Npay and prepared to serve millions of users instead of thousands, we needed a better solution for our analytics needs. OpenSearch, as it was set up at that time wouldn’t scale, both operationally and financially.
As the newly formed Analytics team we opted to approach this by building a data lake on AWS using S3 and Iceberg.
The NDF data lake
The data lake serves as our central repository for Npay operational data from sources such as:
CloudWatch Logs
Aurora SQL databases
DynamoDB tables
Data ingested through API calls
Like all Npay infrastructure, our data lake is built to be deployed on AWS through serverless technologies such as Lambda Functions, Kinesis Streams, Firehose, Glue Streaming ETL jobs with Spark, and Data Migration Service, some of it orchestrated through Step Functions.
The pipelines are designed to synchronise data with a near real-time latency of under a minute. Our use cases often revolve around diagnosing issues as they happen, rather than hours later.
Data in the data lake is primarily accessed through AWS Athena using SQL, with Grafana as the frontend for running queries and visualizing results through dashboards.
This setup has worked well for the Analytics team as we are comfortable in the jungle of SQL, but that is not always the case for the rest of Npay.
The SQL/human gap
Our data lake holds a wide variety of data, and thanks to the flexibility of the Athena SQL engine (based on Presto DB), you can get extremely useful information out of it if you know how to write the right query.
While our developers are very capable, they do not always want to write complex SQL queries when all they really need is to figure out why their features or integrations are misbehaving.
Our leadership team even less so. They do not know SQL at all, and often just want to understand things like how many new payment terminals are operating in the field compared to last week.
So, both developers and leadership turn to the Analytics team for help. After deploying the data lake, some of our day-to-day work involved building queries and dashboards for people trying to answer extremely specific questions. As a team of two, this often pulled us away from more meaningful, long-term work.
If only there were a way to bridge the gap between human language and the arcane incantations needed to bend SQL to our will...
Hacking an agent into being
In the Analytics team, we’ve established a monthly hackathon day. On these days, instead of advancing the daily grind, we work on something we both find interesting or fun regardless of its immediate business value.
Hackathons are something we both look forward to every month. Not only are these off-the-beaten-path projects a pleasant change of pace, but they often turn out to be genuinely useful.
For example, at the height of the AI hype in 2025, we built a small LLM-powered Slack bot called IncidentBot that analyses the incident thread it’s invoked in. It then generates an incident report, including a summary, 5 Whys, and other relevant info. This has helped our on-call responders complete the necessary paperwork much faster.
When coming up with a new hackathon project, we started wondering what would happen if we built an LLM agent to bridge the gap between SQL and human language.
The proof of concept was simple enough:
Python tooling to query our data lake
A system prompt describing the data schema and key business context
A Slack bot as the interface
After a day of pizza and hacking, we deployed it to our development environment and quickly realized it has massive potential.
LakeBot: your human-friendly data interface
Today, LakeBot is the esteemed third member of the Analytics team.
It has its own Slack channel, where it helps people with a wide range of problems. It has long-term memory which persists between sessions, can carry out extended conversations, streams responses, and handles use cases like:
Developers: End-to-end debugging. Thanks to our end-to-end logging across frontend and microservices, it pinpoints which component is failing and why.
Support staff: Helping resolve customer issues. Previously, they would relay their questions to the developers, who would often relay them to us. LakeBot allows them to investigate the problem directly.
Leadership team: Answering high-level operational questions, like how things are going in the field, and generating related reports.
We even ask it to diagnose and suggest solutions to its own issues, because it of course has read access to its own log groups.
We no longer spend as much time building SQL queries for others. Instead, LakeBot has brought in a new set of interesting tasks for our roadmap. For example, adding new features to LakeBot or connecting it to new data sources so it can serve people better.
Some additional features include automatic invocation during production incidents, where it runs its own investigation and helps reduce the time on-call engineers spend diagnosing issues.
It also performs a daily scan of the data, flagging anything that might be worth investigating.
All of this is building toward smarter, AI-driven diagnosis of real production systems.
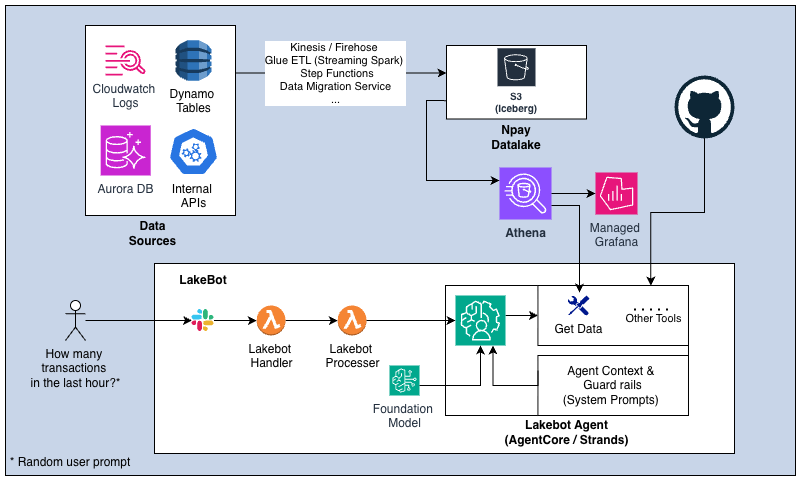
LakeBot architecture overview.
The nerdy tech details
At this point you might be wondering about the technical details. If so, this part is for you.
LakeBot is built with AWS Bedrock AgentCore, with a FastApi-based backend making use of the Strands Agents agent orchestration framework. Currently, it relies on a single agent with a set of tools to access different functionalities, though a multi-agent setup is becoming increasingly relevant as LakeBot evolves.
We use AgentCore long-term semantic memory to persist sessions and details across conversations. In our setup, this memory is shared globally between users, allowing LakeBot to learn from and build on context from other users’ sessions. A side effect is that it may occasionally reference conversations with other users. This is acceptable in our environment, where all sessions are already visible across users, but would be problematic in setups where conversations are expected to remain private.
LakeBot delivers its messages to Slack using a Strands agent stream originating from the AgentCore runtime. This stream is first filtered and parsed by an AWS Lambda Function (the same one that invoked the AgentCore runtime after being pinged on Slack) before appending tokens to a corresponding Slack message stream. LakeBot has multiple modes of communication: In verbose mode, LakeBot posts its tool use input and output payloads (also available as part of the Strands stream) as JSON snippet files to Slack. Otherwise, it lets the user know its thinking process and tool use through Slack’s collapsible plan blocks, which get updated with new items as the thinking progresses.
The foundation model we’re currently using for LakeBot is Anthropic Claude Opus 4.7.
What we learned along the way
While LakeBot is evolving the way we work, building it has also taught us a great deal.
At the time of writing, in early 2026, the AI landscape is evolving rapidly so future readers should take these observations with a grain of salt. That said, we’ve identified a few useful patterns that aren’t immediately obvious:
Managing the system prompt
In our current setup, we provide essential business context along with the schema of the relevant tables as part of the system prompt.
This approach has worked so far, but it doesn’t scale well. As new use cases emerge and the system evolves, we can’t rely on manually updating prompts to cover everything.
Instead, we’re moving toward a more scalable solution: democratizing context through an internal Git repository. It organizes use case knowledge in a hierarchical structure, allowing the agent to retrieve only the relevant information as it navigates the context tree. This also enables teams to contribute directly, shaping how LakeBot behaves for their specific use cases.
Guiding the model's attention
When too much context is presented as equally important, the model struggles to prioritize what matters. In practice, this meant it would often focus only on the most immediately available information.
As an example, when a paginated JSON response contained a large data field before a hasMorePages flag, the model would base its answer solely on the visible data and ignore the need to paginate further. Simply reordering the fields (placing the hasMorePages flag before the data field) resolved the issue.
As it turns out, the coding harness ForgeCode has also discovered this same problem and solution independent of our work.
The takeaway is that with LLMs, emphasis needs to be intentional - clear structure and prioritization matter as much as the content itself.
For Agents obvious is not obvious
After wiring everything together, we asked LakeBot to summarize transactions for the last week. We waited as it fetched the relevant data and returned the results - only to realize the numbers were completely off.
Looking deeper, we discovered the issue: for the LLM, the concept of “now” was effectively fixed to the time the model was trained. It was picking its date ranges relative to that.
The fix was simple. We added a tool that returns the current time and instructed the agent to use it. But it taught us an important lesson: a lot of implicit knowledge we rely on in human communication doesn’t carry over to LLMs.
The same applies to things like awareness of the system it’s running in, its location, or references to previous conversations, unless that context is explicitly provided.
A useful mental model is to review (preferably with the help of a real human) your instructions for hidden assumptions and make them explicit wherever possible.
Moreover, you can evaluate whether a model should rely on external tools for parts of its reasoning or outputs, such as calculations, charts, figures, or structured analysis, instead of generating them directly. This helps reduce hallucinations and avoids variations of the the Strawberry Problem.
Tool feedback makes the agent self-correcting
In the early proof of concept, when the query tool failed, it would simply throw an exception without any details. As a result, LakeBot would fail seemingly at random.
Once we started capturing those exceptions and passing the error messages back to the agent, its behaviour improved significantly. It began retrying with adjusted parameters and correcting its own mistakes.
For example, it would sometimes hallucinate the existence of certain columns. When the error message pointed this out, it would fix the query using the correct column name. We saw similar behaviour across other failure modes, such as scanning too much data or encountering transient network errors.
A better model beats clever prompting
In the machine learning community, there’s a common saying: “More data beats a better algorithm.”
The LLM equivalent might be that a better model often outperforms clever prompt and context engineering by a wide margin.
We saw this firsthand when we moved from Claude Sonnet 3.5 to Claude Opus 4.5 (nowadays 4.7). The improvements in reasoning, query quality, and understanding of user context were significant, resulting in a much better overall user experience.
Security and privacy shape the design, not just the system
Our data lake follows a privacy-by-design approach. Given the requirements of the payments industry, we comply with PCI DSS standards for data storage and handling, alongside GDPR and other obligations enforced through multiple controls.
Importantly, no personally identifiable information (PII) or cardholder data (CHD) is stored in the data lake.
This is an example of a real hard limitation that must be placed on any agent such as this. Simply adding to the system prompt "YOU MUST NOT divulge any CHD from the data you find" would never be a reliable safety net, as agents can and will ignore parts of their system prompt at random.
Building LakeBot introduced additional privacy considerations, given its ability to perform powerful analysis. To ensure it’s used appropriately, we implemented comprehensive logging and restricted access to dedicated Slack channels. It cannot be invoked through any other interface.
Agent Evaluation is a must for its resilience
After we shipped the first version of LakeBot, we realized building the agent solved only half the problem. The other half was making sure it stayed reliable as the system, data, and use cases evolved.
Agent evaluation happens at many different levels. The simplest is writing unit tests for tools, since they typically produce deterministic outputs and can be validated using traditional software testing practices.
Anything involving an LLM, however, is probabilistic by nature. Because of this, we opted for an “LLM-as-a-judge” approach, where a separate model evaluates the agent’s behaviour given the surrounding context.
For example, we maintain a test suite for SQL query generation in which Amazon Nova Pro evaluates the SQL queries produced by Claude Opus against the original problem statement and expected behaviour. This allows us to assess not only whether the query executes successfully, but whether it answers the intended business question correctly.
For observability and evaluation, we use a self-hosted Arize Phoenix deployment for LakeBot tracing and analysis. Phoenix is an open-source framework that provides tooling for tracing agent execution, evaluating responses, and inspecting tool usage. It also includes many useful out-of-the-box utilities for testing both agents and tool execution flows.
At the moment, our evaluation workflow is entirely offline. Whenever we introduce changes to prompts, tooling, context management, or models, we run evaluation suites against historical use cases to ensure existing functionality still behaves correctly.
This setup works well for our current environment, where LakeBot is used internally by a relatively limited audience and conversations are effectively public within the shared Slack channels.
However, at scale, especially when interactions are private or UX is business-critical—online evaluation becomes essential. Systems continuously collect traces and feedback from real-world usage to measure quality, detect regressions, and identify problematic behaviour in production.
Currently, our evaluations focus primarily on individual responses and execution flows. However, Phoenix also provides tooling for full-session evaluation, which becomes increasingly valuable as agents evolve into longer-running, stateful systems. Its interface also makes it easy to inspect complete agent sessions, traces, tool calls, reasoning paths, and other debugging information.
For anyone aiming to evaluate their agents, this course is a good place to start.
What does the future look like
Additional privacy & security considerations
Not all knowledge lives in databases and logs, people rely heavily on conversations, shared context, and experience to get things done.
Going forward, if LakeBot is to capture this kind of tacit knowledge, we’ll need to integrate it with additional internal sources such as Slack messages on public channels and our knowledge base. This introduces new security and privacy considerations.
The same applies if we expose it to end users outside our company network or make it available through other interfaces. In these cases, implementing stronger guardrails will become increasingly important.
Ultimately, however, no number of guardrails can fully ensure an agent will not disclose information it has access to. Any public-facing agent should be limited in its data access to things that the person invoking it already has access to via other means.
Cost efficiency improvements
LakeBot costs are not trivial. With Claude Opus 4.7, an average session currently costs around €5. This was a conscious decision early on, as our primary focus was rapid feature development for internal use cases rather than cost optimisation.
As we scale LakeBot across multiple use cases and potentially introduce multi-agent workflows, improving cost efficiency is becoming increasingly important.
We’re currently exploring several approaches, including:
Model distillation: Take a stronger (teacher) model and reduce it to a generally weaker model that still achieves strong results for a specific task.
Multi-agent architectures with mixed model tiers: While multi-agent architectures can increase token usage through inter-agent communication, not all agents require advanced reasoning and can run effectively on cheaper models.
Prompt caching will help LakeBot in cheaply processing the same data repeatedly and not have to use the full model input token costs repeatedly for the same thing.
Intelligent prompt routing is a feature by AWS which should allow Bedrock to intelligently pick the most cost-effective model for the problem at hand, without needing to rely on a single model for all situations. AWS claims this will help drive down model costs by as much as 30%, so it seems worth looking into.
There are also broader optimisation opportunities around context management, orchestration design, and token efficiency that we’re continuing to evaluate.
Multi-agent architecture
In its current form, LakeBot fetches relevant data from the appropriate tables, performs its analysis, and returns a response to the user. Given this, a multi-agent architecture felt like overkill, so we opted for a single agent with a set of tools handling different tasks.
However, as LakeBot evolves to support a wider range of use cases, the need for a multi-agent architecture is increasingly becoming apparent. Agents perform better when they are focused on a specific task with their own separate contexts.
AWS has multiple recommended setups for multi-agent orchestration, and the architecture we feel is best suited for our use case is the "supervisor" and "specialists" setup. In it a single user-facing agent routes prompts to one or more specialist agents dedicated to individual activities, such as Athena SQL queries or analysing code on GitHub.
That being said, multi-agent setups do have their downsides, too. Multi-agent architectures are known to increase token use by as much as 3x-10x compared to single-agent ones. Therefore, we want to implement a per-session cost breakdown so we can compare both single- and multi-agent setups.
Additional tools, datasets, interfaces, and integrations
We’ve seen a steady flow of requests from users to integrate additional data sources and expand LakeBot’s capabilities. These range from enabling on-the-fly visualizations and generating Grafana dashboards.
At the same time, several data sources have emerged that contain useful information that LakeBot currently cannot access, including AWS MemoryDB, CloudTrail, and S3 buckets with text data.
As for interfaces, the Slack bot works well for now, but it could evolve in multiple directions. For example, it could be integrated as an agent skill or MCP within other agentic harnesses or even exposed as a standalone CLI application for non‑agentic workflows.
Integration with other Agents
LakeBot’s integration with the data lake and GitHub codebase enables our users to make better, data-driven decisions faster. However, we also have other agents serving different use cases and integrating them with LakeBot could unlock even more powerful workflows.
For example, we have ScruffyBot, whose domain is anything code related. One idea we’re exploring is allowing LakeBot to begin debugging an issue using operational and analytics data, then invoke ScruffyBot with the relevant context so it can investigate the codebase and potentially open a pull request in the correct repository.
Similarly, LakeBot could perform a preliminary incident assessment and then hand over to IncidentBot for incident creation, coordination, and summarization.
As these systems evolve, we increasingly see agents not as isolated tools, but as specialized and separately maintained collaborators that can delegate tasks to one another based on their strengths and domain expertise.
Architectural and infrastructural improvements
As LakeBot evolves from a hackathon project to a real internal product with users who depend on it, we need to take a closer look at how it's built and wired into the systems surrounding it.
Operating multiple independent AI agents requires clear insight into agent versions and the approved tools and MCP servers available for discovery. To support this, we plan to adopt the AWS Agent Registry across our accounts.
Slack retries requests if acknowledgments exceed its 3-second timeout, which can occasionally happen due to Lambda cold starts and results in duplicate event deliveries. To address this, we will introduce Amazon SQS backed deduplication using Slack event identifiers to ensure events are processed only once, even when the retries occur.
For securing its network access, we are aiming for complete network isolation for LakeBot. The agent container runs in a private subnet and accesses services such as GitHub through a Lambda Function exposed via a VPC endpoint.
Final thoughts
Building LakeBot has been one of the most enjoyable and rewarding engineering projects we’ve worked on in recent years. What started as a hackathon experiment quickly evolved into something people across the company rely on day to day, and the reception has been far better than we could have hoped for.
Moreover, we were excited to try the AWS DevOps Agent when it launched, but it mostly reinforced that LakeBot already did many of the same things for us, and in practice worked better because it had deeper access to our systems, data, and internal context.
In many ways, building a production-grade AI agent feels less like integrating a single model and more like building a custom harness around it. The orchestration, context management, tooling, observability, evaluation, and guardrails ultimately matter just as much as the model itself.
At the same time, LakeBot also reinforced something important for us: the value of investing in good data infrastructure.
The agent is useful because the underlying data lake already gave us centralized, near real-time, structured access to operational data across the organization. LakeBot did not replace that investment, it magnified the dividends from it by making the data dramatically more accessible to the people who need it.
If the data you care about can be accessed programmatically, it is possible to build your own LakeBot to help more people access it.
The real promise of AI inside organizations is not replacing existing systems but unlocking the value of the knowledge and infrastructure already in place.
Written by
Azeem Akhter - Senior Software Engineer
Aleksi Suutarinen - Data Scientist